
Transform video and images
Content
- "Just-in-time" and "Re-encode" transformations
- Using 2D transformations
- Horizontal and vertical video
- "Rotate and reflect" transformations of "vertical" video
An appearance of static images or frames displayed during a real time playback of video streams can be modified using the following 2-dimensional transform operations (2D Transform):
Just-in-time" and "Re-encode" transformations
Frames of video sequences and individual images can be transformed using two rather different approaches, called "Just-in-time" (JIT) and "Re-encoding" (RE) transformations. A diagram shown in Figure 1 illustrates major video data processing phases in these procedures.
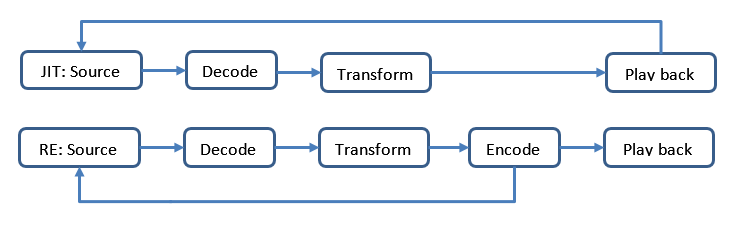
Figure 1.
"Just-in-time" and "Re-encode" transformations.
The main difference between "Just-in-time" and "Re-encode" procedures is that the latter includes a "Re-encoding", an encoding of decoded and transformed video frames or images to the intermediate output stream/file, "physically" separate from the original media source. That intermediate re-encoded stream/file is used as a new source during playback. In the JIT procedure a playback is instant, in the RE procedure a playback is delayed.
"Just-in-time" transformation
In the "Just-in-time" approach, every decoded frame is transformed and then displayed immediately. The sequence of operations "decode-transform-display" is repeated for each frame of video stream. "Just-in-time" approach is a one-stage process where each frame is decoded, transformed and displayed completely, before a processing of the next frame begins. Therefore a playback of video stream in "Just-in-time" approach is done in a real time. It implements an instant playback.There is no any loss of information and quality of the original video when just-in-time decode-transform-display operations are applied (lossless operations). Only the decoded in a real time frames or images are modified to the desired shape, orientation and size before they are displayed. A content of the source video/image stream stays intact.
"Re-encode" transformation
The "Re-encoding" approach is a two-stage process. At the first stage, multiple frames of original video content from the source stream/file are decoded, then they are transformed to the required size and orientation, and then, finally, encoded again to the output stream/file using original or different video data format. The sequence of operations "decode-transform-encode" is repeated for each frame of video stream. At the first stage either all frames or a big group of frames from the original video source are completely decoded, transformed, encoded and, usually, saved to the intermediate video stream/file. At the second stage of re-encoding procedure the video frames are played back from the intermediate video stream/file. Usually the first stage of re-encoding requires a noticeable time to complete. As a result, at the second stage a playback of transformed video is done with a delay relative to the first stage. Therefore a re-encoding procedure implements a non-real time, delayed playback.In most situations re-encoding leads to the loss of information and quality of video in the converted stream relative to the original one. When a re-encoded content is played back, a video quality of displayed frames is usually reduced relative to the original video source. A re-encoding changes a video content in the output stream permanently. Re-encoding requires noticeably more computational resources than "just-in-time" 2D transform. Often, for computationally demanding high quality high definition video, it may be difficult to make re-encoding in real time. In such situations the whole original video stream is re-encoded completely before transformed content is played back.
Using 2D transformations
Both approaches, "just-in-time" and "re-encoding", have their advantages and disadvantages. The right choice depends on the concrete situation.The "just-in-time" 2D transform operations have advantage when:
- an immediate real time playback is required (instant playback)
- an original video quality of displayed frames must be preserved ( loss of original video quality is un-acceptable)
- a permanently transformed video stream/file is not required, and the original video source can be used all the time.
A re-encoding is useful when:
- a whole video stream/file have to be converted permanently, just once; then converted data are used as a primary source
- a loss of original video quality in converted content is acceptable
- there is enough time to wait until a whole original video stream is re-encoded completely, before a transformed content can be played back (non-real time, delayed playback).
For a big video collection consisting of hundreds or even thousands video clips, which must be played occasionally, and in a real time, immediately after accessing (no delays for re-encoding), the only real option is the "just-in-time" 2D transform operations. But if video files must be played frequently and be independent on the different playback platforms, a permanent re-encoding may be useful.
Horizontal and vertical video
The ratio of width to height of video frame is called "aspect ratio". Depending on aspect ratio there are two distinctive types of video, called "horizontal video" and "vertical video".Both terms, "horizontal video" and "vertical video", have two major meanings. The first meaning is technical; it characterizes a format of video itself, independently on a visual perception of that video. The second meaning is psychological and/or aesthetical; it characterizes a visual perception of video content with specific orientation of major objects, independently on the format of that video.
Pure technically, a width of "horizontal" video frame is bigger than its height (width > height). A horizontal video is captured in the "landscape" mode. And vice versa, a height of "vertical" video frame is bigger than its width (height > width). A vertical video is captured in the "portrait" mode. A "vertical video" is an opposite of "horizontal video".
Psychologically (aesthetically), the width of major objects in the content of "horizontally video" has relatively higher impact on their visual perception. And vice versa, the height of major objects in the content of "vertical video" has relatively higher impact on their visual perception.
The best perception of "horizontal video" content is achieved when its video format is also "horizontal". Same condition is applied to the "vertical video". The best perception of "vertical video" content is achieved when its video format is also "vertical".
"Rotate and reflect" transformations of "vertical" video
2D Transform operations are effective in resolving situations when an orientation and a size of the original video stream/images are different from the parameters or orientation of display device used to show video.A diagram shown in Figure 2 explains how a "horizontal" (landscape) and a "vertical" (portrait) video is captured, saved during encoding, and displayed on "horizontal" (landscape) and "vertical" (portrait) monitors.
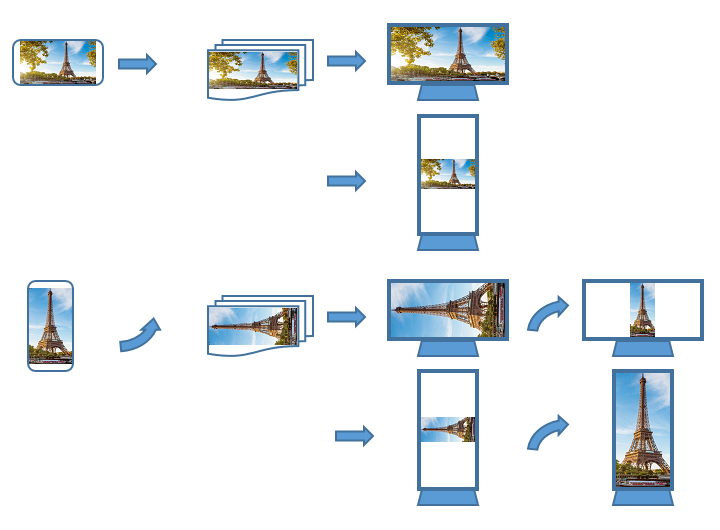
Figure 2.
"Horizontal" (landscape) and "vertical" (portrait) video capture.
In the majority of standard video/image compression formats used for saving a video/images to the permanent file/stream, the individual frames are saved using a landscape ("horizontal") orientation (a width of video frame is bigger than its height). A landscape orientation assumes that an orientation of video camera during a video capture is same as an orientation of frames in the saved video file/stream. That default assumption may create problems when an orientation of video capture device is different from the orientation of frames in the saved file/stream.
For example, frequently a video is captured with a cell phone or a compact camera using a "vertical" orientation. There may be a very good reasons for that, if main object of video capture fits much better namely in the vertically oriented screen. The problem here is that the vertically oriented images are saved with a standard for video stream orientation, which is perpendicular to the vertically oriented camera. During a playback of such vertically captured video on the small mobile device, it can be easy to turn that device to adjust it to the best viewing position. But on the stationary computer monitor or TV with a horizontal orientation, a vertically captured video is turned by 90 degrees, which is very uncomfortable to watch. It is where a "just-in-time" 2D transform of displayed frames can resolve a problem. Using 2D transform "Rotate and reflect", "vertical" frames can be caught "on the fly", converted to the required orientation and size, and displayed in the most comfortable way at the available video monitor.
Another example is met frequently in the video advertisement business. Often video advertised content is perceived the best way on the vertically oriented display devices. The vertically oriented TV are used often for such purposes. Such oriented TVs are used to display the list "menus" in restaurants, bars, stores, various small business shops, airports etc. It is well known that when a primary size of video object coincides with the vertical orientation, it looks better on the vertically oriented display. The pixel space of display device with vertical orientation is used in a most optimal way for showing the "vertical" video objects. In such situations an advertised video content may be captured with vertical orientation, but saved to the file with standard horizontal orientation. It guaranties that pixels of video frames are used in a most effective way for capturing the "vertical" objects, and that "vertical" objects are shown in an optimal way on the vertically oriented display device. During a playback such the "vertical" video content captured for the "vertical" display devices must be transformed into required orientation and size using "just-in-time" 2D transform "Rotate and reflect".